Single-stage Object Detectors
Hello mọi người, bài thứ 3 mình sẽ discuss xíu về single-stage detection models. Bài này t phải đọc paper khá nhiều, nên ra hơi trễ mọi người thông cảm nha. Không phí thời gian của mọi người nữa, t sẽ viết về architectures, configurations, và thêm 1 vài phần hiểu biết của mình về những model sau:
- RetinaNet
- CenterNet
- EfficientDet
- Yolov3
Bắt đầu nhé 🔥🔥🔥
RetinaNet (2018)
Contribution lớn nhất của RetinaNet thật ra không phải architecture, mà là nằm ở focal loss (thậm chí tên bài báo cũng là Focal Loss for Dense Object Detection 😅). Nhưng thôi mình cũng nói về architecture mà họ dùng ha. Ở backbone, một model để extract feature-Feature Pyramid Network(FPN) được sử dụng, FPN được đề xuất bởi Facebook năm 2017. Mình đi sơ qua các bước hình thành của loại backbone này xíu ha.
Đầu tiên model được phát triển từ 1 ý tưởng rất đơn giản, gọi là single feature map. Nghe vậy thôi, chứ thật ra nó chỉ là 1 Convolutional Network với các layer nhỏ dần và trả về output cho prediction ở layer cuối cùng(cũng là layer nhỏ nhất), không khác mấy những convolutional network mình thường gặp phải không

Và sau đó mình có 1 cái model update pyramidal feature hierarchy. Cơ mà tại sao lại predict ở từng layer, vậy thì mình sẽ lấy kết quả ở layer nào?

Thật ra đây chính là model được dùng trong SSD object detector. Cứ 1 prediction, kết quả sẽ trả về sẽ là 1
list
box và class, vị trí tương ứng của từng box. Sau đó model sẽ có 1 layer Non-max Suppression để lọc ra những
box có
vị trí và class gần với ground-truth box nhất. Khi sử dụng model multi-scale layer như vầy, mình sẽ không cần
lo
scale của input mình. Tuy nhiên, nhược điểm của model này là không thể detect những object nhỏ (input cho dù
lớn
vẫn có thể có object nhỏ nha mọi người 😀) do thiếu sự kết nối về semantic giữa các layer (semantic connection
này
chỉ được thể hiện ở Non-max Suppression). Vậy nên Facebook đã cải thiện nhược điểm này bằng Feature Pyramid
Network. 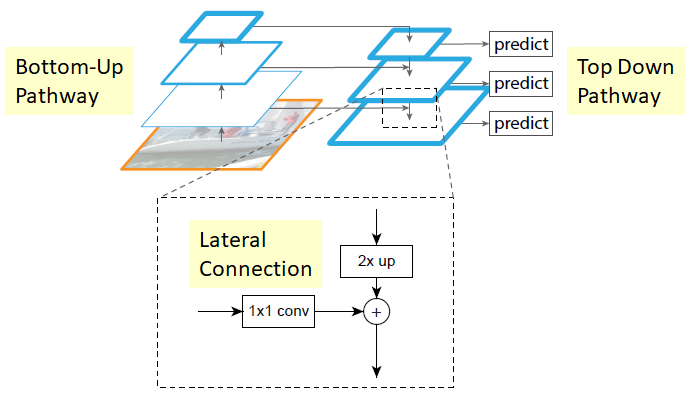
FPN có 2 pathway: bottom-up và top-down. Ở bottom-up, model được sử dụng có thể là bất kì backbone model nào (và RetinaNet sử dụng ResNet). Nhưng giữa những layer đó, mình sẽ bổ sung thêm lateral connection với top-down pathway để thể hiện cá semantic connection mà mình đã nhắc đến. Tuy nhiên, ở RetinaNet, output của top-down pathway không phải là prediction result, mà nó sẽ là input cho 2 sub-network: class subnet(để classify box) và box subnet(cho box regression), giống nhau và được chạy song song với nhau. Tuy nhiên focal loss chỉ được dùng ở class subnet, còn ở box subnet thì dùng non-max suppression để update box

Vậy là tạm xong architecture của RetinaNet, giờ mình qua CenterNet nha.
CenterNet (2019)
Mặc dù CenterNet không đạt được kết quả nổi bật, hướng tiếp cận của CenterNet lại khá thú vị. CenterNet có thể nói là một trong số ít những model CNN không sử dụng anchor box. Như t từng đề cập, những model dùng anchor box sẽ phải declare trước 1 list các anchor boxes, và sau đó sẽ regress để những anchor boxes này fit những object tìm được, và đây chính là nhược điểm của anchor-based models. Nói cách khác, khi dùng anchor box, câu hỏi được đặt ra là “bao nhiêu anchor box là đủ và anchor box size bao nhiêu là đúng?”, và ngặt nổi câu này rất khó trả lời. Vậy nên không chỉ CenterNet, mà nhiều model (không nói đến Transformer), sử dụng keypoints để thay thế anchor box. Về CenterNet thì mình cần tìm hiểu 2 điều: backbone của nó - HourGlass và strategy để detect keypoints.
HourGlass Model
HourGlass là backbone model thường được dùng cho human pose detection, và đúng như tên gọi, nó có hình dáng
giống
đồng hồ cát (nhỏ ở giữa và lớn ở 2 đầu :v) 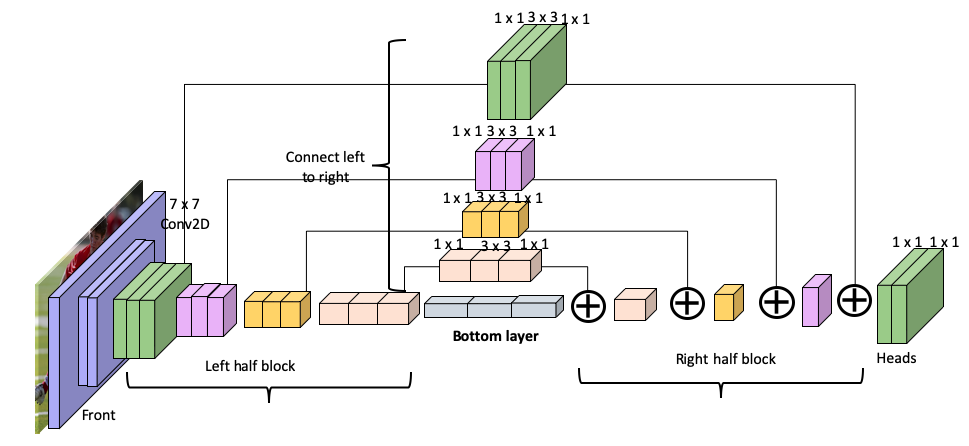
Ở đây, HourGlass model có 2 phần là downsampling và upsampling, nhiều bài thì viết là encode-decode hoặc conv-deconv, trong trường hợp này thì chúng như nhau. Phần bên trái được gọi là downsampling còn phần bên phải là upsampling. Mỗi block ở downsampling là 1 residual block , không biết mọi người còn nhớ không, nhưng residual block là các block có skip connections ấy, như hình trên thì những block trung gian, thật ra chính là block ở downsampling, sẽ được cộng vào ở các layer tương ứng. Wait, vậy thì nó khác gì FPN đâu trừ việc bị lật ngang lại :v ? Thật ra HourGlass chính là 1 trong những tiền thân của FPN. FPN khác biệt với HourGlass ở 3 điểm:
- FPN sử dụng lateral connection, trong khi ở HourGlass chỉ là cộng đơn thuần
- Output của FPN được thể hiện qua từng layer ở “top-down pathway”, còn của HourGlass thì ở cuối “downsampling”
- Một điểm thú vị nữa là HourGlass Model có thể được stacked, trong khi FPN thì không do output của FPN đã
được
lấy ra ở từng layer.

Tóm lại, model có dạng downsampling-upsampling này không dám đảm bảo về speed, nhưng có khả năng detect những loại hình ảnh có đặc tính dense và thường sẽ tăng accuracy ở những môi trường đó.
Key-points detection strategy
Model CenterNet nó dùng 3 điểm (keypoints) để đặc tả 1 object thay vì 2 điểm như tiền thân của nó là CornerNet. Để có thể đưa ra 3 keypoints để thể hiện object 1 cách chính xác nhất có thể, họ dùng 2 strategies : center pooling và cascade corner pooling. Để tìm hiểu 2 strategy này thì mình đi sơ qua architecture của CenterNet xíu ha.

Như trong hình thì đầu tiên hình sẽ được đi qua HourGlass backbone model, sau đó thì được tẻ ra 2 subnet là cascade corner pooling và center pooling, 2 subnet này sẽ có những heatmaps tương ứng, và từ những heatmaps này, mình có thể lấy được corner keypoints hoặc center keypoint.
Đối với center pooling strategy, mình sẽ tìm max value theo cả chiều ngang và dọc, sau đó sẽ cộng dồn với
nhau về
center keypoint của object. Như hình dưới đây, các điểm đỏ mờ và vàng mờ là những max của chiều ngang hoặc
dọc, và
mình sẽ cộng các điểm max cùng màu với nhau để ra center keypoint. Ở đây thì tui có câu hỏi dành cho mọi người
đây, làm sao để mình biết được phải cộng theo dướng nào? Ví dụ 2 điểm đỏ mờ sao không cộng thành 1 điểm đỏ đậm
ở
phía gần mắt con bé? Hay 2 điểm mờ màu vàng không cộng lại để ra 1 điểm vàng đậm gần rìa cây vợt, rõ ràng là ở
rìa
cây vợt có màu vàng sẽ cho điểm nổi bật hơn so với trong lòng vợt mà phải không? :v  Câu hỏi trên tui để
dành
cho mọi người ha :v Giờ mình đến strategy tiếp theo: cascade corner pooling. Cascade corner pooling là bản cải
tiến của corner pooling của CornerNet. Thay vì chỉ đi tìm edge để đưa ra 2 điểm top-left và bottom-right, CCP
đưa
ra 2 điểm này bằng cách tìm cả trên boundary và bên trong, cách làm đã được sửa đổi theo tác giả của paper theo link này nha. (thông cảm nha, CenterNet
tui
viết hơi nhiều quá rồi)
Câu hỏi trên tui để
dành
cho mọi người ha :v Giờ mình đến strategy tiếp theo: cascade corner pooling. Cascade corner pooling là bản cải
tiến của corner pooling của CornerNet. Thay vì chỉ đi tìm edge để đưa ra 2 điểm top-left và bottom-right, CCP
đưa
ra 2 điểm này bằng cách tìm cả trên boundary và bên trong, cách làm đã được sửa đổi theo tác giả của paper theo link này nha. (thông cảm nha, CenterNet
tui
viết hơi nhiều quá rồi)
2 strategies này, tuy không đến nỗi là computational costly nhưng lại khiến model chậm lại đáng kể, đặc biệt là nếu với những hình có high resolution. Ví dụ như mình có 1 video có resolution 1 frame là 1920x1080, như vậy cứ 1 hình, mình phải loop qua tổng cộng 2073600 pixels 2 lần chỉ để đưa ra center keypoints. Sau đó mình sẽ phải loop thêm 2 lần nữa (2 lần ở đây 1 là cho internal, 1 là cho boundary) để tìm ra corner keypoints. Nếu khắc phục được điểm yếu này thì tui nghĩ CenterNet sẽ được sử dụng nhiều hơn
EfficientDet (2020)
Bây giờ mình qua 1 gia đình mới: EfficientDet. Đây là model được đề xuất bởi Google Brain Team, và trong đó có Lê Viết Quốc, nhưng dĩ nhiên bài này không phải bài nổi trội của ổng do ổng làm về NLP nhiều hơn. Anyways, model này cũng thuộc dạng làm mưa làm gió ấy nhá. Contribution của model này gồm 2 phần chính: BiFPN (bi-directional feature pyramid network), và compound scaling.
Bi-directional Feature Pyramid Network
Trước khi vào architecture cụ thể của Bi-FPN, mình xem qua model tổng quát của nó trước ha
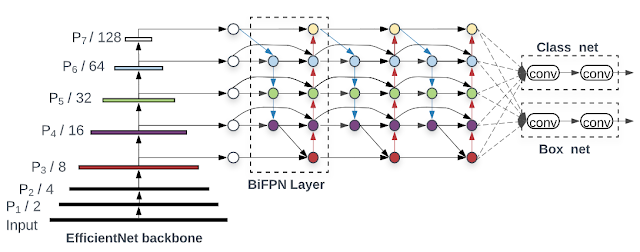
Tạm thời mọi người đừng để ý đến những số P kia nha. Ở đây backbone model của mình là EfficientNet, backbone
model này cũng do 2 tác giả Mingxing Tan và Lê Viết Quốc phát triển, nhưng EfficientNet tui sẽ để dành bài sau
nha. EfficientNet thật ra cũng chính là bottom-up pathway cho FPN nếu mình nhìn tổng thể toàn model. Bây giờ
mình
nhìn qua BiFPN layer 1 xíu, mình có thể thấy thay vì chỉ là top-down pathway thông thường như FPN, bên trong
BiFPN
lại có thêm bottom-up pathway, loại connection này được gọi là Cross-Scale Connection (CSC). CSC được dùng để
cải
thiện hạn chế của FPN khi chỉ có luồng thông tin đơn chiều. Vậy nên, trong trường hợp thông tin có thể di
chuyển
theo cả 2 hướng bottom-up và top-down như vầy, mình gọi nó là bi-directional. Cụ thể như thế nào thì mọi người
tham khảo thêm PANet và NAS-FPN nhé. Trong bài báo về EfficientDet, CSC được đề cập có gây ảnh hưởng lớn đến
computations và tăng số lượng parameter, một layer đầy đủ khi sử dụng CSC nó sẽ như vầy:

Và ở đây mọi người có thể thấy 2 node màu cam nó thực chất chỉ đóng vai trò trung gian vận chuyển thông tin từ 2 node \(P_7\) và \(P_3\) đến 2 node liền kề của 2 node cam này, nói cách khác, chúng nó không có giá trị tổng hợp thông tin. Vậy nên, ở trong BiFPN, 2 node này đã được lượt bỏ. Bên cạnh đó, giữa input và những bottom-up pathways có 1 đường nối, đường này được cho là giúp tổng hợp thông tin giữa các layer với nhau, nhưng không cần phải thêm cost. Thú vị đúng không, rõ ràng là những intuition này khá đơn giản, nhưng năm ngoái mới có team nghĩ ra :v
Sơ lược về BiFPN chỉ có nhiêu thôi, giờ mình qua compound scaling nhé.
Compound Scaling
Đa phần khi đưa ra những version tốt hơn model baseline, những baseline model này sẽ được train với ảnh lớn hơn hoặc thêm layers và số layer cần được thêm là bao nhiêu thì cần dùng những phương pháp search để đưa ra số layers tối ưu. EfficientDet tiếp cận vấn đề này một cách thú vị hơn, bằng cách scale backbone, BiFPN, box/class prediction network, và input image linearly thông qua \(\phi\) và những công thức tương ứng (mọi người tham khảo paper để biết công thức như thế nào nha, linear nên cũng không khó đâu). Cá nhân tui thấy ý tưởng này cũng khá hay, chỉ cần 1 vài công thức, mình đã có thể đưa ra hàng loạt các model tương tự nhưng cho kết quả tốt hơn và phù hợp với nhiều mục đích khác nhau

Vậy là EfficientDet đã được tóm tắt xong. 3 model trên là 3 model có liên quan đến architecture downsampling-upsampling. Bây giờ mình bước qua 1 family model mà không thể không nhắc đến khi làm Object Detection - YOLO.
YOLOv3 (2018)
Thú thật là khi nhắc đến Yolo, tui thường cảm thấy nó bị lạm dụng hơi quá, cứ hễ đụng đến Object Detection là mọi người nhảy vô làm Yolo trước (vậy thì vô vị quá đi mất). Nhưng suy đi ngẫm lại, quả thật Yolo phải đạt được những kết quả nhất định thì mọi người mới dùng nhiều như vậy. Hoặc ít nhất thì Reddie đã không làm ta thất vọng


Đặc điểm của YOLO đó là architecture rất đơn giản, nhưng phương pháp thì lại phức tạp. Những model tui kể
trên,
đa phần sẽ là nhiều model được ghép lại với nhau, mỗi loại model trong 1 architecture sẽ thực hiện 1 vài task
nhất
định. Ngược lại, Yolo chỉ sử dụng 1 model xuyên suốt. Nhiệm vụ chính yếu của Yolo là chia 1 khung hình thành
nhiều
regions(grid) và dự đoán bounding box cũng như class trên từng grid này rồi sau đó chạy qua Non-max
suppression để
đưa ra bounding box trùng class cuối cùng.
Yolov3 về cơ bản không quá khác đời đầu, nhưng được thêm 1 vài techniques để tăng accuracy như multi-scale predictions và update backbone model. Trong đó, multi-scale prediction thật ra được apdapt từ FPN, trả về predict cho từng scale. Yolov3 dùng 3 scales, ở mỗi scale, 3 anchor boxes sẽ được dùng để predict object. Vậy thì trên toàn model, mình sẽ có 9 anchor boxes. Để chọn ra 9 anchor boxes này, họ dùng K-means để cluster các box trong dataset theo width và height, lấy centroids của 9 clusters để ra các anchor boxes, và chia ngẫu nhiên cho 3 scales.
Vậy nên, đối với Yolo, input mình càng tổng quát thì kết quả nhận sẽ càng tốt
Ở v1, output của 1 predictions sẽ là 1 tensor
\[S*S*(B*5+C)\]
trong đó \(S\) là 1 cạnh của 1 grid. Vậy nên trên 1 hình, mình sẽ có \(S*S\) grids. Cứ 1 grid, mình sẽ predict ra \(B\) box, 1 box sẽ có 5 elements: 4 params của bounding box \((x,y,w,h)\) với \(x,y\) là tọa độ của center của 1 box, và 1 params để xác định trong box này có phần tử nào hay không. Mỗi grid này cũng kèm theo 1 list C probability của các class, lưu ý ở đây 1 grid chỉ có 1 list C thôi. Vậy thì nếu trong cùng 1 grid xuất hiện 2 object thì sao? Khi chuyển sang v3, output của mình sẽ có dạng \[S*S*[3*(5+C)]\], với 3 ở đây là 3 scales, tương ứng nếu detect được sẽ có 3 box, và khi này 1 box sẽ có 1 list probability C (update hơn so với v1 r nhỉ :v)
Về backbone, Yolov3 đã update backbone Darknet từ 19 CNN layer sang 53 CNN layers và có sử dụng thêm Residual block (nên chậm hơn v2 😂)

Phiên bản đẹp hơn của architecture nằm ở đây:
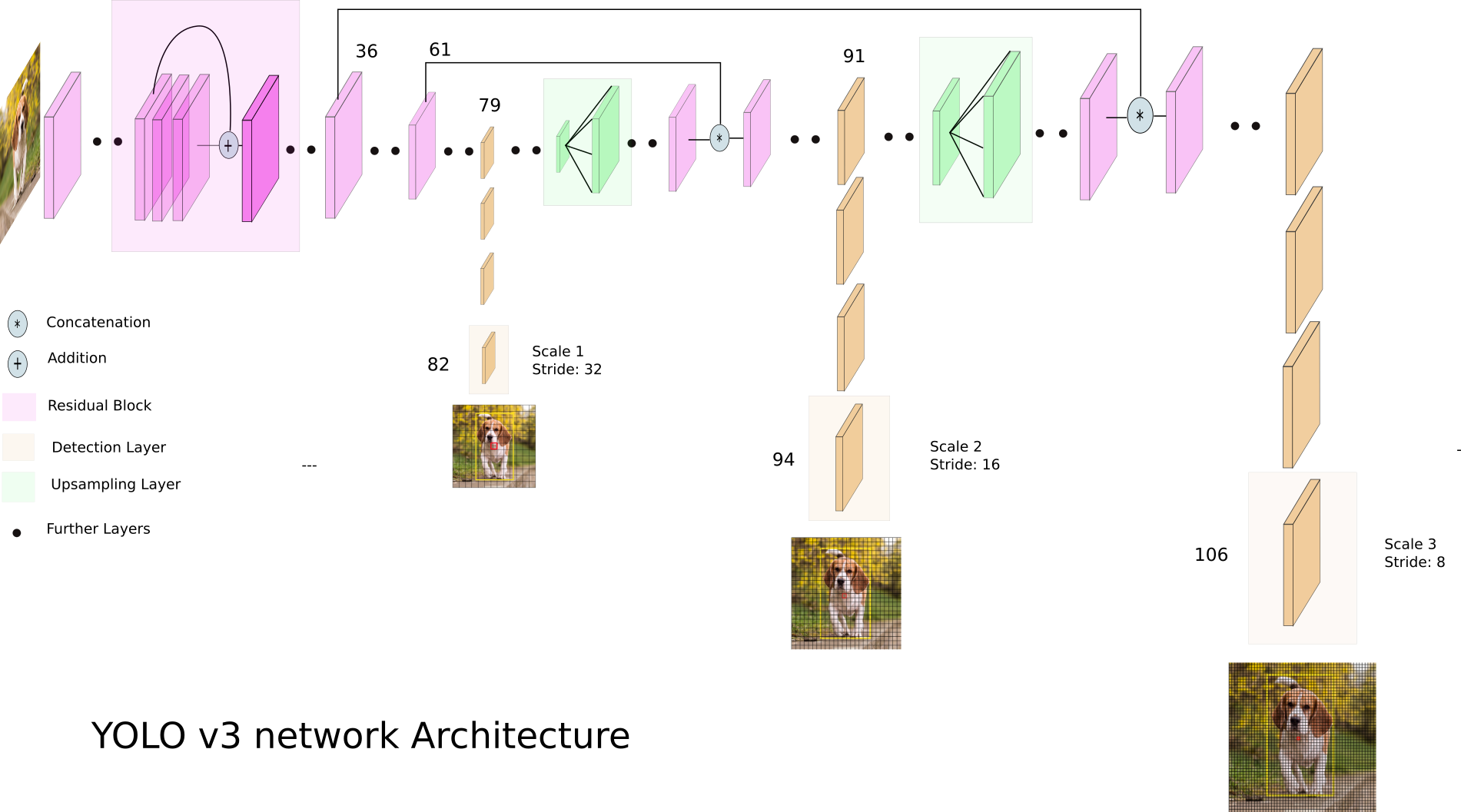 Đồng thời cũng đề cập đến 1 số
thứ mà
họ apply vào Yolov3 nhưng lại không ra kết quả tốt, trong đó có focal loss, nhưng thật sự thì cả tác giả cũng
không dám khẳng định tại sao 🙃
Đồng thời cũng đề cập đến 1 số
thứ mà
họ apply vào Yolov3 nhưng lại không ra kết quả tốt, trong đó có focal loss, nhưng thật sự thì cả tác giả cũng
không dám khẳng định tại sao 🙃
Năm ngoái, Redmon (yeah cái ông có resume my little pony ấy) đã khẳng định sẽ dừng research CV do lo ngại về việc CV, đặc biệt là công trình của ổng đã được dùng vào quân sự như thế nào Link ở đây. Family Yolov4 trở đi là do các tác giả khác phát triển và đã gây không ít tranh cãi
—-—
Ở bài này tui tạm thời dừng ở đây, 1 phần là do tui vẫn cảm thấy Yolov4 và Yolox tui chưa nắm kỹ lắm để viết cho mọi người, nên cần thêm thời gian, 1 phần nữa là do Yolov4 có dùng khá nhiều terms mới, cũng như thiên về việc sử dụng architectural units, nên chắc để sang tuần sau để update chung với architectural units luôn.
Take-away đây Dưới đây là structure chung cho những model object detection, mình sẽ dựa vào đây để config các model sao cho phù hợp với project của mình. Về architecture, mình sẽ tập trung vào neck và backbone. Bên cạnh đó, mình sẽ analyze thêm loss function và dùng vào model của mình.

Cuối cùng, cảm ơn mọi người đã bỏ thời gian đọc, tui hi vọng bài viết này giúp mọi người hiểu thêm về 1 số Single-stage object detection. Nếu mọi người có thắc mắc hay điều gì thú vị thì cứ trao đổi với nhóm nha.